在人工智能语音合成领域,F5-TTS作为一个新兴的开源项目,正以其卓越的性能和创新的技术架构吸引着开发者和研究人员的关注。该项目基于Flow Matching技术,实现了高质量、流畅自然的文本转语音功能。
项目GitHub地址:https://github.com/SWivid/F5-TTS
一、F5-TTS项目概述¶
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching,是一个先进的文本转语音(TTS)系统,它通过Flow Matching技术实现了高度自然和流畅的语音合成。该项目不仅提供了高质量的语音输出,还在训练和推理速度上进行了优化,使其成为实际应用中的理想选择。
项目的主要特点包括:
- F5-TTS:基于Diffusion Transformer与ConvNeXt V2架构,训练和推理速度更快
- E2 TTS:采用Flat-UNet Transformer,最接近论文中的原始实现
- Sway Sampling:一种推理时的流步骤采样策略,显著提高了性能表现
- 广泛的多语言支持:除英语和中文外,还支持法语、德语、日语、西班牙语、意大利语、俄语、芬兰语和印地语等多种语言。如需了解完整的语言支持列表和各语言模型的详细信息,可参考项目的SHARED.md文档。
- 零样本语音克隆:通过短音频样本即可实现高质量的声音克隆
二、安装与环境配置¶
F5-TTS支持多种安装方式,适应不同用户的需求:
1. 环境准备¶
首先创建一个独立的Python环境(推荐Python 3.10):
# 创建conda环境
conda create -n f5-tts python=3.10
conda activate f5-tts
2. PyTorch安装¶
根据您的硬件环境选择合适的PyTorch版本:
NVIDIA GPU:
pip install torch==2.4.0+cu124 torchaudio==2.4.0+cu124 --extra-index-url https://download.pytorch.org/whl/cu124
AMD GPU (仅Linux):
pip install torch==2.5.1+rocm6.2 torchaudio==2.5.1+rocm6.2 --extra-index-url https://pytorch.org/whl/rocm6.2
Intel GPU:
pip install torch torchaudio --index-url https://pytorch.org/whl/test/xpu
Apple Silicon:
pip install torch torchaudio
3. F5-TTS安装¶
您可以选择以下两种安装方式之一:
方式一:作为pip包安装(仅用于推理)
pip install f5-tts
方式二:本地可编辑安装(用于训练和微调)
git clone https://github.com/SWivid/F5-TTS.git
cd F5-TTS
pip install -e .
4. Docker支持¶
项目也提供了Docker部署方案:
# 从Dockerfile构建
docker build -t f5tts:v1 .
# 从GitHub Container Registry运行
docker container run --rm -it --gpus=all --mount 'type=volume,source=f5-tts,target=/root/.cache/huggingface/hub/' -p 7860:7860 ghcr.io/swivid/f5-tts:main
# 快速启动Web界面
docker container run --rm -it --gpus=all --mount 'type=volume,source=f5-tts,target=/root/.cache/huggingface/hub/' -p 7860:7860 ghcr.io/swivid/f5-tts:main f5-tts_infer-gradio --host 0.0.0.0
三、使用方法¶
F5-TTS提供了两种主要的使用方式:Gradio Web界面和命令行界面(CLI)。
1. Gradio Web界面¶
启动Gradio应用¶
# 默认启动
f5-tts_infer-gradio
# 指定端口和主机
f5-tts_infer-gradio --port 7860 --host 0.0.0.0
# 创建分享链接
f5-tts_infer-gradio --share
访问地址:http://127.0.0.1:7860
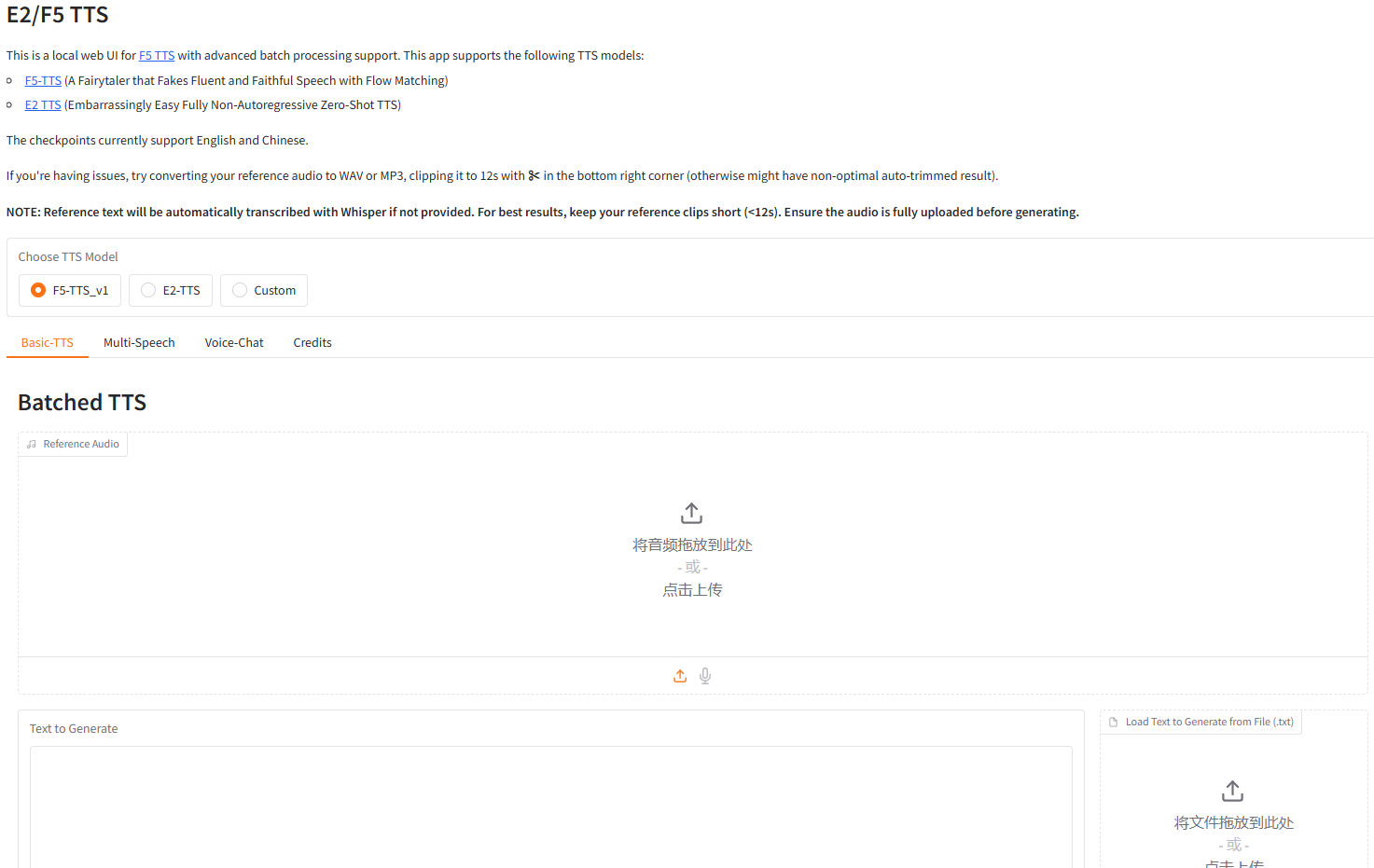
注意:首次启动F5-TTS时,系统会自动从Hugging Face下载所需的模型文件(包括Vocos和F5TTS模型)。下载过程可能需要一些时间,具体取决于您的网络速度。模型文件较大(约1.35GB),请确保您的网络连接稳定。
如果您无法访问Hugging Face,可以通过设置环境变量使用镜像站点。根据您的操作系统,执行以下命令之一:
Linux/macOS系统:
export HF_ENDPOINT=https://hf-mirror.com
f5-tts_infer-gradio
Windows系统(PowerShell):
$env:HF_ENDPOINT = "https://hf-mirror.com"
f5-tts_infer-gradio
Windows系统(命令提示符):
set HF_ENDPOINT=https://hf-mirror.com
f5-tts_infer-gradio
功能概览¶
Gradio界面提供了友好的用户交互体验,支持以下核心功能模块:
- Basic TTS with Chunk Inference:基础文本转语音功能,支持分块推理
- Multi-Style / Multi-Speaker Generation:多风格/多说话者语音生成
- Voice Chat powered by Qwen2.5-3B-Instruct:由Qwen2.5-3B-Instruct驱动的语音聊天功能
界面功能详解¶
📱 Basic TTS with Chunk Inference(基础TTS)
- 上传参考音频文件(支持WAV或MP3格式)
- 输入要生成的文本内容
- 可选:提供参考文本(如不提供将自动使用Whisper转录)
- 重要提示:参考音频建议控制在12秒以内以获得最佳效果,否则可能导致非最优的自动裁剪结果
🎭 Multi-Style / Multi-Speaker Generation(多风格/多说话者语音生成)
支持通过特殊格式生成不同情感和风格的语音。用户可以使用情感标签或个性化设置来控制语音的输出风格,包括语速、音调等参数,实现多样化的语音合成效果。
💬 Voice Chat powered by Qwen2.5-3B-Instruct(语音聊天)
- 上传参考音频作为AI的声音模板
- 通过麦克风或文本与AI进行对话
- AI将使用参考声音进行回复,由Qwen2.5-3B-Instruct模型驱动
2. 命令行界面(CLI)¶
CLI方式适合自动化和批量处理场景:
# 使用参数运行
# 如果将--ref_text设置为空字符串,将使用ASR模型进行转录(需要额外GPU内存)
f5-tts_infer-cli --model F5TTS_v1_Base \
--ref_audio "provide_prompt_wav_path_here.wav" \
--ref_text "The content, subtitle or transcription of reference audio." \
--gen_text "Some text you want TTS model generate for you."
# 使用默认设置运行。src/f5_tts/infer/examples/basic/basic.toml
f5-tts_infer-cli
# 或使用自定义.toml文件
f5-tts_infer-cli -c custom.toml
# 多语音示例。参见src/f5_tts/infer/README.md
f5-tts_infer-cli -c src/f5_tts/infer/examples/multi/story.toml
四、性能与部署¶
1. 性能基准¶
根据项目提供的基准测试结果,在单个L20 GPU上使用26个不同的prompt_audio和target_text对进行解码,16 NFE(Number of Function Evaluations)的情况下:
| 模型 | 并发数 | 平均延迟 | RTF | 模式 |
|---|---|---|---|---|
| F5-TTS Base (Vocos) | 2 | 253 ms | 0.0394 | 客户端-服务器 |
| F5-TTS Base (Vocos) | 1 (批量) | - | 0.0402 | 离线TRT-LLM |
| F5-TTS Base (Vocos) | 1 (批量) | - | 0.1467 | 离线Pytorch |
2. 部署方案¶
项目支持使用Triton和TensorRT-LLM进行部署,以满足生产环境的需求。详细的部署指南可以在项目的文档中找到。
Docker部署示例:
# 从Dockerfile构建
docker build -t f5tts:v1 .
# 从GitHub Container Registry运行
docker container run --rm -it --gpus=all --mount 'type=volume,source=f5-tts,target=/root/.cache/huggingface/hub/' -p 7860:7860 ghcr.io/swivid/f5-tts:main
# 快速启动Web界面
docker container run --rm -it --gpus=all --mount 'type=volume,source=f5-tts,target=/root/.cache/huggingface/hub/' -p 7860:7860 ghcr.io/swivid/f5-tts:main f5-tts_infer-gradio --host 0.0.0.0
NVIDIA设备的Docker Compose文件示例:
services:
f5-tts:
image: ghcr.io/swivid/f5-tts:main
ports:
- "7860:7860"
environment:
GRADIO_SERVER_PORT: 7860
entrypoint: ["f5-tts_infer-gradio", "--port", "7860", "--host", "0.0.0.0"]
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
volumes:
f5-tts:
driver: local
五、训练与微调¶
F5-TTS不仅支持推理,还提供了模型训练和微调的功能:
1. 使用Hugging Face Accelerate进行训练¶
项目提供了详细的训练和微调指南,帮助用户根据自己的需求定制模型。在开始之前,建议参考项目的训练与微调指南以获取最佳实践。
2. 使用Gradio界面进行微调¶
# 使用Gradio Web界面快速开始
f5-tts_finetune-gradio
3. 开发环境设置¶
使用pre-commit确保代码质量(将自动运行linters和formatters):
pip install pre-commit
pre-commit install
在每次提交前,运行:
pre-commit run --all-files
注意:某些模型组件为了适应tensor操作,对E722规则有linting例外。
六、应用场景¶
F5-TTS的高质量和灵活性使其适用于多种场景:
- 内容创作:为视频、播客和有声书生成高质量旁白
- 辅助技术:为视障人士提供文本到语音的转换服务
- 虚拟助手:为聊天机器人和虚拟助手提供自然的声音
- 语言学习:生成标准发音的语言学习材料
- 游戏开发:为游戏角色创建独特的声音
- 客户服务:自动化客服系统的语音响应
- 情感配音:通过Multi-Speech功能为不同场景生成带有情感色彩的语音,如广告配音、动画配音等
- 个性化语音助手:创建具有个人声音特色的AI助手,用于日常交互
七、总结¶
F5-TTS作为一个先进的开源文本转语音项目,通过Flow Matching技术实现了高质量、流畅自然的语音合成。其快速的训练和推理能力,加上灵活的部署选项,使其成为开发者和研究人员的理想选择。
无论您是希望为应用程序添加语音功能,还是进行语音合成的研究,F5-TTS都提供了强大而易用的工具。随着项目的不断发展和社区的积极参与,我们可以期待看到更多创新的功能和改进。
在AI225导航,我们致力于为您介绍最新、最有价值的AI工具和项目。F5-TTS代表了语音合成技术的最新进展,值得开发者和研究人员关注和尝试。